
티스토리 뷰
컬렉션 프레임워크 List의 특징과 이를 구현한 주요 클래스에 대해서 알아보려고 한다.
List
Collection 인터페이스의 하위 타입으로, 순서가 있는 자료구조이다.
특징
• List에 저장된 요소의 순서는 항상 보장된다. 저장 공간이 유동적으로 변하며, 순서가 있는 자료구조이다.
• List는 중복 요소 저장을 허용하며, null 저장도 가능하다.
• List는 저장 공간이 유동적으로 변한다. 요소가 추가되거나 삭제될 때 자동으로 크기가 조정된다.
• List는 인덱스를 활용하여 요소에 접근할 수 있다.
• List 와 그 구현체들은 java.util 패키지에 존재하므로, 사용 시 import 를 해줘야한다.
List 의 구현체
ArrayList
동적 배열을 기반으로 구현된 자료구조로, 가장 널리 쓰이는 List의 구현체로 쓰인다.
ArrayList 클래스를 보면 배열을 사용한다는 것을 알 수 있다.
transient Object[] elementData;특징
• 연속적인 공간을 갖는다.
• 데이터를 순차적으로 저장하며, 가변 크기의 배열이다.
• 기본 생성자를 호출하여 객체를 생성할 경우 기본 용량은 10이다.
• 인덱스를 활용하여 요소를 삽입, 삭제하게 되었을때에는 모든 요소의 위치는 변경된다.
• ArrayList에 저장된 값은 객체의 참조값(메모리 주소)를 저장한다.
• 조회를 많이 하는 경우에 사용하는 것이 좋다.
예제
import java.util.List;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
Car tucson = new Car();
Car grandeur = new Car();
List<Car> cars = new ArrayList<>();
cars.add(tucson);
cars.add(tucson);
cars.add(grandeur);
cars.add(null);
}
}Car 객체를 두개 생성하고, List를 참조하여 ArrayList 객체를 생성하였다.
ArrayList 객체에 tucson이라는 변수값을 가진 객체를 2번, grandeur이라는 변수값을 가진 객체를 1번, 마지막엔 null값을 추가하였다.
위 코드를 기반으로 heap 메모리에 할당된 데이터 구조는 다음과 같다.
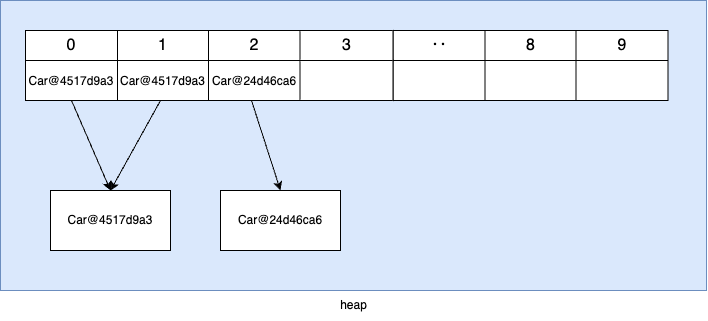
여기서 tucson 데이터를 삭제해보면 다음과 같이 모든 요소의 위치는 변경된다.
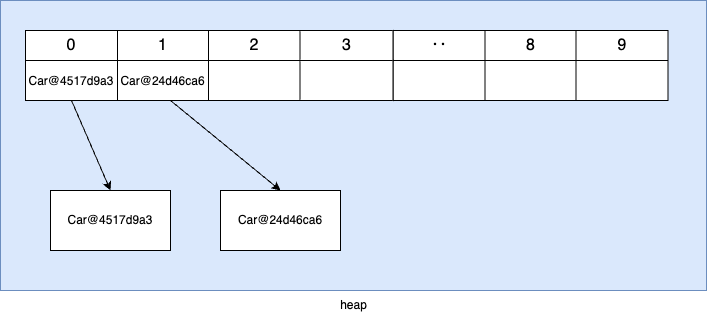
1번 인덱스에 있는 tucson 객체를 삭제했을 경우에, 2번인덱스부터 존재하는 요소들의 위치가 한칸씩 앞으로 이동한다. 만약, 특정 인덱스를 기반으로 요소를 추가하였을 경우에도 해당 인덱스의 다음 위치에 있는 요소부터 한칸씩 뒤로 이동하게 된다.
따라서, ArrayList를 사용할 때에는 요소를 추가하거나 삭제 후 원하는 요소에 접근할 때 인덱스 사용을 조심해야한다. 특정 인덱스를 기준으로 모든 요소의 위치가 변경되기 때문이다.
LinkedList
연결 리스트 자료구조로, 각 요소는 노드로 이루어져있다.
LinkedList 클래스를 보면 Node 객체를 사용한다는 것을 알 수 있다.
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item; //객체의 정보를 저장하는 필드
Node<E> next; //다음 노드 정보를 저장하는 필드
Node<E> prev; //이전 노드 정보를 저장하는 필드
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}특징
• LinkedList는 양방향 연결 리스트 구조로 구현되어있다.
• 노드는 연속적인 공간이 아닌 각자 독립된 공간에 존재하며, 서로 참조값으로 연결된 구조이다.
• 노드는 객체의 참조값(메모리 주소)와 다음 노드에 대한 참조값으로 이루어져있다.
• 요소를 검색할 때에는 순차적으로 데이터를 찾아야하기때문에 속도가 ArrayList에 비해 느리다.
• 인덱스를 활용하여 요소 추가, 삭제할 때에는 해당 인덱스 앞/뒤 노드의 참조값만 변경하면 된다.
예제
import java.util.List;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
Car tucson = new Car();
Car grandeur = new Car();
List<Car> cars = new LinkedList<>();
cars.add(tucson);
cars.add(tucson);
cars.add(grandeur);
}
}
노드는 연속적인 공간에 할당되지 않고, 각자 자신들이 참조해야할 노드의 주소를 갖고 연결되어있다.
여기서 tucson 데이터를 삭제해보면 다음과 같이 삭제된 노드의 앞/뒤 노드는 참조해야 할 주소값이 변경된다.
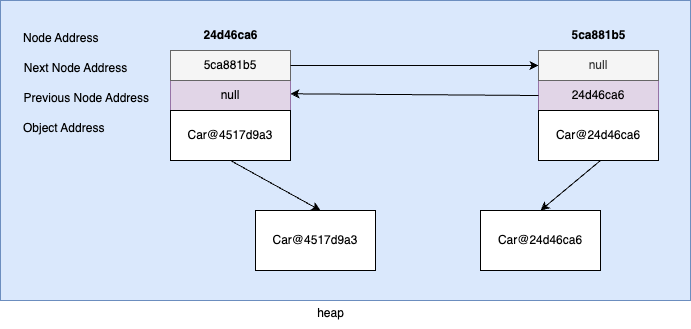
앞에있던 노드는 자신이 참조하던 노드가 삭제되었으니, 삭제된 노드의 다음노드의 주소를 참조하도록 변경한다.
뒤에있던 노드는 자신이 참조하던 노드가 삭제되었으니, 삭제된 노드의 이전노드의 주소를 참조하도록 변경한다.
요소를 추가하였을 때에도 동일하게 노드가 참조하던 주소의 값만 변경된다.
Vector
동적 배열을 기반으로 구현된 자료구조이다.
ArrayList와 동일한 내부구조로 이루어져있지만, 동기화 기능이 추가된 버전이다.
protected Object[] elementData;특징
• 주요 메서드는 synchronized 키워드가 선언되어있다.
• 멀티 스레드가 동시에 Vector 객체를 조작할 수 없다.
• 동기화 기능으로 인하여 성능 저하가 발생할 수 있다.
예제
public class Main {
public static void main(String[] args) {
List<Car> cars = new Vector<>();
Runnable task = () -> {
for (int i = 0; i < 100; i++) {
cars.add(new Car());
}
};
Thread[] threads = new Thread[10];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(task);
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("number of car created : " + cars.size());
}
}총 10개의 스레드를 생성하고, 각 스레드는 100개의 Car 객체를 만들어서 vector 에 저장하는 코드이다.
결과 값은 항상 1000이 나온다는 것을 알 수 있으며, 이는 vector에서 동기화 기능을 제공하기 때문이다.
만약 Vector 가 아닌 ArrayList 로 구현을 하였을 때에는 1000이 아닌 매번 다른 숫자의 결과값이 발생하는데, ArrayList는 동기화 기능이 없기 때문이다.
List 의 구현체들에 대한 정리를 해본다.
1. ArrayList는 LinkedList의 내부적인 구조가 다르다.
ArrayList는 동적 배열 기반으로 연속된 공간의 메모리를 사용하며, LinkedList는 노드기반으로 독립적인 공간의 메모리를 사용한다.
ArrayList는 요소를 찾는데 O(1)의 시간 복잡도를 갖지만 추가하거나 삭제를 진행하고나서 배열을 정렬해야하기 때문에 O(n)의 시간 복잡도를 갖는다. 반면에 LinkedList는 인덱스를 활용하여 요소를 추가하거나 삭제할 경우 해당 인덱스의 앞/뒤 노드가 참조하는 값만 변경해주면 되지만, 해당 인덱스에 접근하기까지 O(n)의 시간 복잡도를 갖는다.
따라서 요소를 찾는데는 ArrayList가 빠르지만, 중간에 요소를 추가 또는 삭제할 때에는 항상 LinkedList가 빠르다고 이야기할 수 없다. LinkedList는 순차적인 접근을 하기 때문에, 인덱스가 클수록 검색하는데 시간이 오래 걸리기 때문이다.
즉, 리스트의 크기와 인덱스의 크기를 기반으로 속도는 다를 수 있다.
2. ArrayList와 Vector의 내부적인 구조는 거의 동일하지만 둘의 차이점은 동기화 여부이다.
ArrayList와 Vector 둘 다 동적 배열을 사용하여 요소를 저장한다.
ArrayList는 동기화되지 않는 자료구조로, 여러 스레드가 접근하여 조작할 수 있기 때문에 멀티스레드에 안전하지 않다.
Vector는 동기화된 자료구조로, 대부분의 메서드는 synchronized 키워드를 사용하여 멀티스레드에 안전하다.
요즘은 동기화가 필요한 경우에 Vector보다 ArrayList에 동기화 작업을 추가하는 방식으로 사용한다고 한다.
TODO. 직접 구현해보고 링크 달기
'Language > Java' 카테고리의 다른 글
| Hash 기반 자료구조 (1) | 2024.11.09 |
|---|---|
| Hash에 대해서 (0) | 2024.11.08 |
| Object 클래스 (0) | 2024.11.05 |
| 예외와 에러에 대하여 (5) | 2024.11.03 |
| 상속에 대하여 (0) | 2024.10.31 |
- Total
- Today
- Yesterday
- spring boot
- Security
- AutoConfiguration
- 티스토리챌린지
- fail-fast
- syncronized
- Hash
- 정적변수
- 고정 세션
- java
- 다중화
- 자동구성
- Spring
- nginx
- fail-safe
- 인터페이스
- 로드 밸런서
- 추상클래스
- 인스턴스변수
- 오블완
- Red-Black Tree
- HashMap
- HashSet
- @conditional
- nosql
- object
- Load Balancer
- Caching
- Sticky Session
- JPA
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |