
티스토리 뷰
캐시는 데이터를 빠르게 제공하기 위해 사용된다고 알고 있었다.
캐시는 웹 사이트나 앱에서 데이터를 빠르게 제공하기 위해 중요한 역할을 한다. 나같은 경우 조금이라도 느릴 경우 왜 이렇게 느린가하며 재시도를 하거나 껐다가 다시 켜는 경우도 있었다. 다른 외부적인 요인도 포함되겠지만, 속도에 대한 문제는 캐시를 제외시킬 수는 없다.
캐시는 속도와 같은 시스템의 효율성을 향상시키기 위해 너무나 중요하기 때문에 많은 시스템에서 사용되고 있을 것이다. 그래서 이번에 캐시와 캐싱 전략에 대해 알아보려고 한다.
캐시와 캐싱
캐시는 자주 사용하는 데이터를 미리 복사해 놓은 임시 저장소를 말하며, 캐싱은 데이터를 캐시에 저장하고 활용하는 행위나 과정을 의미한다.
캐싱을 잘 활용하면 응답 시간을 줄이고, 데이터베이스의 부하를 줄이며 비용 절감 및 시스템 성능을 높일 수 있다.
캐시 사용 시 고려할 점
1. 데이터 갱신보다 참조되는 경우가 많을 경우 캐시 사용을 고려해야 한다.
2. 영속적으로 보관할 데이터는 캐시에 저장하기보다 데이터베이스와 같은 지속적 저장소에 두는 것을 고려해야 한다.
3. 캐시에 저장되는 데이터의 만료 정책을 정해야 한다.
만료 정책이 없으면, 데이터는 계속 캐시에 남게 되므로 오래된 데이터를 제공할 수도 있고 데이터의 저장 공간이 부족해질 수 있다. 따라서 만료 정책을 정해야 하는데, 만료 기한이 너무 짧으면 데이터베이스의 접근이 빈번해져 성능이 저하될 수 있고 만료 기한이 너무 길면 원본 데이터와 차이가 날 가능성이 높아지므로 적절하게 설정하는 것이 중요하다.
4. 데이터의 원본과 캐시에 저장된 사본에 대한 일관성에 대해 고려해보아야 한다.
원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않은 경우 이 일관성은 깨질 수 있다. 특히 분산 시스템에서 원본과 사본에 대한 일관성을 유지하는 건 어렵지만 매우 중요한 문제가 된다. - 참고해보기
5. 단일 장애 지점, SPOF(Single Point Of Failure)에 대해 어떻게 대처할 것인지 고려해야한다.
캐시 서버를 한대만 두는 경우에 이 서버는 SPOF가 될 가능성이 있어 모든 요청이 캐시 서버를 거치도록 설계되어있으면 응답 시간은 물론이고 데이터 손실이 발생할 수 있다. 이를 방지하기 위해서 분산 캐시 서버 환경으로 하고 데이터 복제와 failover 기능을 활용하도록 한다.
6. 캐시 메모리의 크기를 고려해야한다.
7. 데이터 방출 정책을 고려해야한다.
방출 정책은 캐시가 꽉 차게되면, 추가로 캐시에 데이터를 넣어야 할 경우 어떤 데이터를 캐시로부터 내보내야 하는지를 정하는 것이다. 가장 널리 쓰이는 것은 LRU(Least Recently Used), 마지막으로 사용된 시점이 가장 오래된 데이터를 내보내는 것이다. 다른 정책으로는 LFU(Least Frequently Used - 사용된 빈도가 가장 낮은 데이터를 내보내는 정책)와 FIFO(First In First Out - 캐시에 가장 먼저 들어온 데이터를 가장 먼저 내보내는 정책)가 있으니 경우에 맞게 적용하면 된다.
Cache Hit, Cache Miss 와 Cache Hit Ratio
캐시 히트(Cache Hit)와 캐시 미스는(Cache Miss) 데이터를 읽을 때 사용되는 용어로, 밑에 캐싱 전략에서 언급될테니 미리 알아두자.
캐시 히트(Cache Hit)는 캐시에 데이터가 있는 경우를 말한다.
캐시 미스는(Cache Miss)는 캐시에 데이터가 없는 경우를 말한다. 만약 캐시 미스가 자주 발생하는 상황이라면 이는 캐시의 이점을 활용하지 못해 성능이 떨어지게 된다.
캐시 적중률(Cache Hit Ratio)은 캐시가 히트되는 비율을 의미하는데 캐시 적중률이 높으면 데이터베이스의 접근 횟수를 줄일 수 있다.
캐시 적중률은 다음과 같이 계산된다.
캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
Read Strategy
Cache-Aside
어플리케이션이 데이터를 요청할 때 캐시에 없으면 직접 데이터베이스에 접근하여 데이터를 가져와 캐시에 저장하는 방식이다.

1. 어플리케이션은 먼저 캐시를 확인한다. 캐시 히트가 발생하면, 데이터를 캐시로부터 읽고 클라이언트한테 응답한다.
2 ~ 5. 캐시 미스가 발생하면, 데이터베이스에서 데이터를 직접 가져와 클라이언트한테 응답하고 해당 데이터를 캐시에 저장한다.
이 방식에서 데이터를 쓸 때에는 어플리케이션이 직접 데이터베이스에 데이터를 쓴다. 하지만 이는 캐시와 데이터베이스의 데이터가 일치하지 않을 수 있는 단점이 있는데, TTL(Time to Live)을 설정하고 TTL이 만료될 때까지 캐시에 있는 데이터를 제공한다. 만약 캐시가 최신 상태의 데이터를 보장해야한다면 캐시 항목을 무효화하거나 다른 적절한 쓰기 전략을 사용해야한다.
Read-Through
어플리케이션이 데이터를 요청할 때 캐시에 없으면, 캐시는 데이터베이스에서 데이터를 가져와 저장하고 응답하는 방식이다.

1. 어플리케이션은 먼저 캐시를 확인한다. 캐시 히트가 발생하면, 데이터를 캐시로부터 읽고 클라이언트한테 응답한다. (Cache-Aside 와 동일하다.)
2~5. 캐시 미스가 발생하면, 데이터베이스로부터 데이터를 읽어 캐시에 저장하고 클라이언트한데 응답한다.
이 방식은 데이터 요청이 반복적으로 발생하는 시스템에 가장 적합하다. 예를들어 뉴스와 기사가 있다.
하지만, 데이터가 처음 요청될 때 항상 캐시 미스가 발생하고 데이터를 로드하는 시간이 길어질 수 있다는 단점이 있다. 개발자는 첫 데이터를 로드할 때 캐시를 워밍하여 이를 처리할 수 있는데 수동으로 쿼리를 실행하여 진행할 수 있다.
Cache Aside 와 Read Through 를 간략하게 비교해보자면,
Cache Aside는 어플리케이션이 캐시와 데이터 베이스에 직접 통신하는 구조이고, Read Through는 어플리케이션-캐시-데이터베이스 구조로 이루어져있다. 이 구조로 인하여 캐시 미스가 발생하면 Cache Aside는 클라이언트에게 데이터를 응답하고 캐시에 저장을 하는 반면에, Read Through는 캐시에 데이터를 저장하고 클라이언트에게 데이터를 응답한다.
Write Strategy
Write-Around
어플리케이션은 데이터를 직접 데이터베이스에 작성하고, 읽은 데이터만 캐시에 저장하는 방식이다.
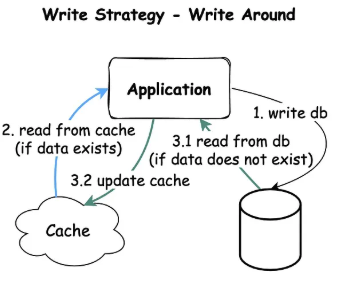
1. 어플리케이션은 데이터를 데이터베이스에 작성한다.
2. 어플리케이션은 캐시에 데이터를 확인한다. 캐시 히트가 발생하면 데이터를 캐시로부터 읽고 클라이언트한테 응답한다.
3.1 ~ 3.2. 캐시미스가 발생하면 어플리케이션은 데이터베이스로부터 데이터를 읽고 캐시에 저장한다.
Read-Through와 같이 사용될 수 있으며, 데이터가 한 번 쓰여지고 자주 또는 전혀 읽히지 않는 상황에서 좋은 성능을 제공한다. 예를 들어, 실시간 로그나 채팅방 메시지가 있다.
Write-Through
데이터가 캐시에 저장될 때, 동시에 데이터베이스에 저장되는 방식이다.

1. 어플리케이션은 데이터를 캐시에 직접 저장한다.
2. 캐시는 데이터베이스의 데이터를 업데이트한다. 데이터 저장이 완료되면 캐시와 데이터베이스 모두 동일한 값을 가지며 캐시는 항상 일관성을 유지하게 된다.
이 방식은 캐시에 데이터가 저장될 때, 데이터베이스에도 저장되기 때문에 캐시와 데이터베이스의 데이터 일관성을 유지할 수 있다. 데이터 무결성을 보장해야하는 시스템에서 큰 장점이 될 수 있다.
하지만 캐시와 데이터베이스 모두에 데이터를 저장해야 하는 과정에서 쓰기 작업 속도가 느릴 수 있어 쓰기 작업이 빈번하지 않은 시스템에서 사용하는 것이 좋다.
또한 이 방식은 Read-Through 방식과 함께 사용하면 효과적이다.
Read-Through 방식의 장점과 이 방식의 장점인 데이터 일관성을 보장을 결합함으로써, 자주 사용되는 데이터를 빠르게 제공하는 동시에 데이터베이스와 캐시 간의 동기화를 유지할 수 있다.
따라서, 읽기 작업이 많고 데이터의 정확성이 중요한 시스템에서 유용하게 두 결합 방식이 활용된다.
Write-Back (Write-Behind)
어플리케이션은 데이터를 캐시에 계속해서 저장하고, 캐시는 데이터를 나중에 데이터베이스에 저장하는 방식이다.
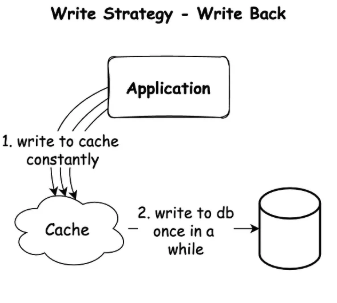
1. 캐시에 데이터를 계속 저장한다. 캐시에 저장하고 클라이언트에 바로 응답을 한다.
2. 캐시에 있는 데이터는 일정 시간이 지난 이후 한번 씩 데이터베이스에 비동기적으로 작성된다.
이 방식은 어플리케이션 관점에서 볼 때, 데이터를 작성하는 것이 빠른데 그 이유는 캐시에 데이터를 작성하는 즉시 응답을 받기 때문이다. 쓰기 작업이 많은 경우에 이 방식이 적합하다.
Write Back 과 Write Through 를 간략하게 비교해보자면,
Write Back 은 캐시에 쓰여진 데이터가 데이터베이스에 비동기적으로 작성되고, Write Through는 동기적으로 작성된다.
https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
Caching Strategies and How to Choose the Right One
Compare the pros and cons of various caching strategies to choose the best one for your use case.
codeahoy.com
https://blog.bytebytego.com/p/top-caching-strategies
Top caching strategies
What are the top caching strategies?
blog.bytebytego.com
'Server' 카테고리의 다른 글
| 로드밸런서(load balancer)와 고정세션(sticky session) (1) | 2024.12.17 |
|---|---|
| 정적 컨텐츠와 동적 컨텐츠 그리고 캐싱 방법 (0) | 2024.12.14 |
- Total
- Today
- Yesterday
- Hash
- object
- nginx
- 추상클래스
- Spring
- 티스토리챌린지
- syncronized
- Sticky Session
- 인터페이스
- Load Balancer
- java
- HashSet
- HashMap
- 로드 밸런서
- Caching
- 고정 세션
- 인스턴스변수
- spring boot
- 다중화
- @conditional
- fail-safe
- fail-fast
- 오블완
- Red-Black Tree
- nosql
- Security
- 자동구성
- AutoConfiguration
- JPA
- 정적변수
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |